Google Colaboratory es un entorno de máquinas virtuales basado en Jupyter Notebooks que permite el uso gratuito de las GPUs y TPUs de Google, con librerías como: Scikit-learn, PyTorch, TensorFlow, Keras y OpenCV (y demás). Disponible hasta el momento bajo Python 2.7 y 3.6.
Alto ahi, aclaremos primero que es Jupyter Notebooks:
"Es un entorno de trabajo interactivo que permite desarrollar código en Python (por defecto, aunque permite otros lenguajes también) de manera dinámica, a la vez que integrar en un mismo documento tanto bloques de código como texto, gráficas o imágenes. Es un SaaS utilizado ampliamente en análisis numérico, estadística y machine learning, entre otros campos de la informática y las matemáticas."
Ahora si, continuamos con Google Colab. La principal ventaja que ofrece esta herramienta es que libera a nuestra máquina de tener que llevar a cabo un trabajo demasiado costoso tanto en tiempo como en potencia o incluso nos permite realizar ese trabajo si nuestra máquina no cuenta con recursos suficientemente potentes. Y lo mejor de todo, it's free!
Otro de los beneficios que tiene es que es colaborativo, nos permite realizar tareas en la nube y compartir nuestros cuadernos si necesitamos trabajar en equipo.
Empezando a trabajar con Colab
Para comenzar a trabajar y tener nuestro espacio de
trabajo en Colab, simplemente debemos contar con una cuenta de Google y acceder
al servicio de Google Drive (o directamente a través de este enlace), hacer click en "Nuevo", desplegamos el menú
de "Más" y seleccionar "Google Colaboratory", así, nos
creará un nuevo cuaderno (notebook).
También podemos crear una carpeta específica y luego
crear nuestros cuadernos allí.
Antes que nada, aclaremos que es un cuaderno o "notebook", Un cuaderno es un documento que contiene código ejecutable (por ejemplo, Python) y también elementos de texto enriquecido (links, figuras, etc.). Es nuestro «entorno de trabajo» en Colab y se ve de la siguiente forma:
Vemos que en la parte superior se encuentra el nombre del cuaderno creado (vamos a cambiarlo para identificarlo luego) y su formato .ipynb, que viene de IPython Notebook , que es un formato que nos permite ejecutar cuadernos tanto en IPython, como en Jupyter y Colab. (Un lujo, o no?).
¿Que son las celdas?
Un cuaderno está compuesto por celdas, estas celdas
son donde incluimos nuestro código y lo ejecutamos. Para ejecutar una celda
podemos pulsar el botón con el icono de Play (1) que se encuentra a la izquierda
o pulsando Ctrl+Enter (ejecutar celda) o Shift+Enter (ejecutar celda y saltar a
la siguiente).
Luego de la ejecución, encontraremos el resultado del código
(si es que tiene).
 |
| (1) |
 |
| (2) |
En la parte izquierda de una celda ejecutada se puede observar un número entre corchetes (2), este número indica la cantidad de veces que se ejecutó esa celda (También nos indica el orden de ejecución). Si pasamos el cursor por esta parte izquierda de la celda también podemos ver información sobre quién ejecutó la celda, en qué momento y cuánto tardó la ejecución.
Podemos cambiar el orden de las celdas con las flechas de la parte superior, hacia arriba o hacia abajo, o modificarlas con el menú desplegable de la parte derecha de cada celda, borrándolas o añadiendo comentarios y enlaces.
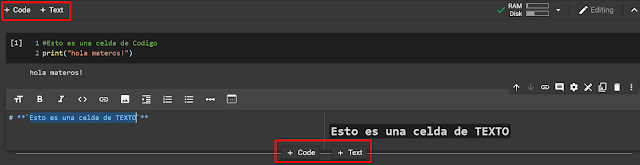
Desde los botones de la parte superior o en el menú «Insertar» podemos añadir nuevas celdas, tanto específicas para código como para texto. La distinción que hace Colab sobre ellas es que las celdas de código son ejecutables, mientras que las de texto muestran directamente el texto que incluyamos y además incluyen un pequeño editor de texto.Utilizando el entorno de ejecución
Cuando creamos un nuevo cuaderno, este es «estático», es decir, vemos su contenido, pero no estamos conectados a ningún entorno de ejecución. Nuestro cuaderno se conecta a una VM de Google Compute Engine (la infraestructura de máquinas virtuales de Google en la nube) cuando ejecutamos una celda o pulsamos sobre el botón de «Conectar». Al hacerlo, el cuaderno toma un momento en conectarse y después muestra, de ahí en adelante, el espacio de RAM y disco que estamos consumiendo. La máquina en un inicio cuenta con 12 GB de RAM y 50 GB de almacenamiento en disco disponibles para el uso.
La duración de la máquina virtual a la que nos conectamos, es decir, el tiempo máximo que podemos estar conectados a una misma máquina desde un cuaderno es de 12 horas. Aquí hay que tener cuidado, sobre todo si estamos llevando a cabo ejecuciones que toman mucho tiempo: si pasamos más de 90 minutos sin utilizar un cuaderno, el entorno se desconecta. Para que no se desconecte basta con dejar la ventana del navegador abierta o celdas ejecutándose. La ventaja que tiene para estos casos es que, si dejamos una celda ejecutándose y cerramos el navegador, la ejecución continuará y si posteriormente abrimos el navegador tendremos nuestro resultado.
Cambiando el entorno de ejecución y versión de Python
Por defecto, el entorno al que se conecta Colab utiliza un kernel con Python 3 y no permite la ejecución con GPU. En un inicio, Colab utilizaba Python 2, pero ahora permite crear nuevos cuadernos tanto en Python 3 como en Python 2, desde el menú de «Archivo».
De esta forma, crearíamos un cuaderno utilizando la versión de Python que deseemos. No obstante, podría ocurrir que queramos cambiar la versión de Python una vez creado el cuaderno o utilizar la GPU en lugar de la CPU (que es la que se usa por defecto) para realizar ejecuciones más ponentes, como la creación de modelos de aprendizaje profundo. Colab nos permite cambiar los ajustes del entorno para utilizar una GPU de forma gratuita. Para ello, vamos al desplegable de «Entorno de ejecución» y seleccionamos «Cambiar tipo de entorno de ejecución».
Aquí podemos cambiar la versión entre Python 3 o Python 2 y, lo más importante, cambiar el «Acelerador por hardware» de «None» a «GPU». La otra opción es «TPU», que son unidades de procesamiento de tensores, específicas de Google para ejecutar modelos de machine learning.
Utilizando datasets en Colab
Algo muy importante y que utilizaremos bastante, es trabajar con nuestros datasets en nuestro cuaderno.
Vamos a ver las distintas formas de hacerlo:
1. Importar desde Google Drive
Una manera es importando nuestros archivos desde Google Drive, utilizando fragmentos de código podemos hacer esta intregración con Drive:
2. Desde Github (Archivos < 25MB)
Otra manera rápida de importar nuestros datasets y utilizarlos es mediante Github.
Primero, vamos a ir a nuestro repositorio, ubicar nuestro dataset y hacer click en "View Raw". Copiamos el link del dataset y lo guardamos en una variable llamada url in colab. El último paso es utilizar Pandas (Más adelante hablaremos más sobre esta librería), utilizaremos la funcion read_csv para guardarlo en un DataFrame.
3. Desde nuestra PC local
Para utilizar nuestro dataset alojado localmente, usaremos el siguiente código:
Al ejecutarlo, nos aparecerá un prompt para seleccionar nuestro archivo. Hacemos click en "Choose Files", seleccionamos nuestro dataset y lo cargamos. Esperamos que el archivo se haya subido al 100% (Aca deberíamos ver el nombre del archivo una vez que fue cargado correctamente).
Por ultimo utilizaremos el siguiente código, utiliza pandas para guardarlo en un DataFrame (Verificar que el nombre del archivo sea igual al subido anteriormente).
En resumen...
Vimos que es Colab, para que sirve, como funciona y sus funciones, será provechoso en un futuro ya que nos brinda la oportunidad de trabajar con Python en la nube y realizar trabajos de machine learning, análisis de datos y más, de forma gratuita y colaborativa.
También vimos 3 maneras de cargar nuestros datasets para futuros proyectos.
Espero que les haya servido esta entrada, ya pueden empezar a probar y trabajar con sus notebooks (o cuadernos) con Colab!
Pueden dejar sus comentarios o sugerencias, hasta pronto!










Comentarios
Publicar un comentario